

Integrated Digital Financial Reporting
Automation of the Financial Reporting Process
Digital Financial Reporting is moving to a new phase of development. The move towards standardisation using Inline XBRL (HTML with XBRL tags) and its benefits were reviewed in a recent article. In Europe, ESEF regulation and the proposed EU’s Corporate Sustainability Reporting Directive (CSRD) reporting framework mean that some 50,000 of the largest European companies will be using the iXBRL format for their reporting.
Like companies reporting to the US SEC, UK Companies House, Irish Tax Office and many others, these companies are evolving their internal and external reporting processes as part of the move to iXBRL.
The initial phase saw software suppliers and companies primarily focussed on how to tag and validate their report. XBRL tools were simply bolted on to existing financial and disclosure management software to provide the required format.
The previous article discussed the many limitations with tagging PDF-files or the ‘document-first’ approach. The article went on to explain the new ‘digital-first’ approach emerging using HTML-based content management systems, which solves these limitations and offers many process advantages. One of the biggest benefits of digital formats for companies is the automation of the reporting process, including the XBRL tagging.
This paper explores new ways of working, new software tools, and using new formats for integrating numerous systems in the reporting chain.
Automating Financial Reports
For many years the data produced by accounting and financial management software would eventually end up in numerous spreadsheets and documents. These were manually edited and combined with narrative and communications content to produce a company’s annual financial report, typically in PDF format. Disclosure Management software has helped companies collect the information for these documents from its various sources and to help integrate into one place. The final process of turning the information into a fully designed PDF still involves numerous company resources, outside designers using print-based tools like InDesign, and requiring manual audits of both content and data.
Over the last 15 years, authorities around the world have gradually been moving to more efficient and reliable ways to collect this information from companies, so that it can be used for regulatory analysis. The source information in these reports sits in numerous financial and accounting systems, and in numerous document formats. To collect these reports in a sensible manner required an open intermediate standard and hence, Inline XBRL (iXBRL) has become the chosen international format to meet these challenging demands.
XBRL, put simply, adds ‘tags’ to the numeric or text content in a report. These tags identify information that stakeholders may be interested in. Inline XBRL format requires these tags to be embedded in an HTML document, which means it can be read by people and also machines, enabling data systems to extract and analyse the content inside.
The iXBRL document offers much more than print or PDF. Using a special XBRL ‘viewer’ the reader can see the financial tags that the company has used, and with analysis can better understand the ‘model’ behind the financial statements.
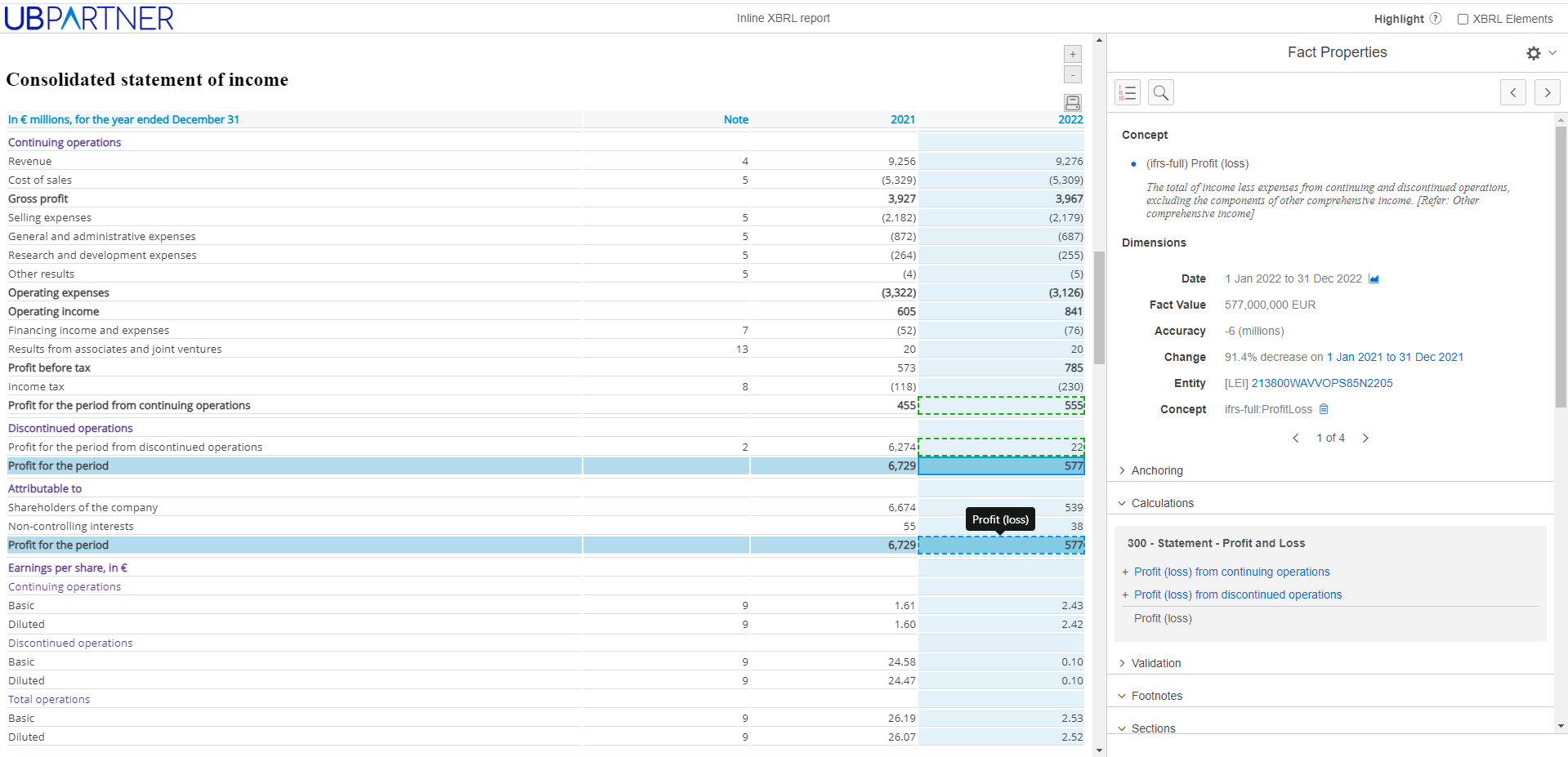
An iXBRL Viewer shows, such things as, the calculations between elements of a statement, it can show where there are errors in these calculations, and identify potential elements that are missing, requiring more detailed exploration of other sections, such as, the disclosure notes.
Document-First Limitations
To date, companies have mostly adopted a very basic ‘bolt-on’ approach to producing their XBRL reports. This takes a print-first format (a PDF) and converts it to HTML, and then applies the tags. Unfortunately, despite its speed and low cost, there are many digital limitations to this approach. The output isn’t easily usable or accessible for humans, and much of the information inside tags is of poor quality, so of little use to machines.
The irony of this legacy process is that much of the content being taking into print software like InDesign/PDF started life as well-structured information in the accounting or disclosure management system. Turning it into a PDF removes the data structure that is needed for the final report.
Why not take the content from the structured source and push tagged information directly into the required report?
Developing digital-first software that covers the complete life cycle of an annual financial report and provides smooth and automatable processes for XBRL generation takes time. However, these new approaches are developing quickly, as discussed in our previous paper.
Modern iXBRL publishing tools such as ‘Pomdoc Pro’ and ‘Reportl’ are among the first to adopt new digital-first approaches – providing more user-friendly, well-designed reports, perfectly tagged, and with an easy-to-use, interactive interface. So, how do you get the data from the accounting software or disclosure management into these digital publishing tools in an efficient way?
Integrating XBRL Reporting
Today, spreadsheets are the most common format for transferring data from finance systems to reporting software. Their ubiquity and familiarity are their strength as companies look to automate processes built on structured data. However, as XBRL tagging increases and report publishing becomes more digitally demanding, the processes and tools will need to improve further.
The Inline XBRL format offers potential advances on Excel, especially for transferring the structure, model, and layout for financial statements. Inline XBRL includes the details of the tags, the tagged information, and the structured model (XBRL Taxonomy) used to tag it.
By using iXBRL, the financial statements can be pre-modelled in XBRL, and the data refreshed at any time. This enables the automated validation of the data, and last-minute data changes won’t disrupt the delivery timescales of an important report.
Principle of Digital-First Reporting
First, if financial software can produce the required statements in iXBRL, then advanced digital-first report publishing systems, such as Pomelo and Reportl, could import these as part of their solution. Some accounting software is already moving in this direction, by initially producing tagged financial statements in iXBRL.
Second, using Word-based tools for reports that don’t require high quality design or digital functionality. Talentia is using the UBPartner tools to embed the tagging of the primary statements and produce a Word template so that text and other content can be added by the user. Talentia also provides a Word tagging tool to tag the Word document. The final Word document is converted by the UBPartner tools to iXBRL to deliver the complete report. Word doesn’t offer the same future-proof accessibility and online functionality of HTML publishing software, but for smaller listed companies that only need a simple annual financial statement the output is good enough.
In the short-term, companies whose financial systems do not provide iXBRL output can use tools such as UBPartner’s XT ESEF to tag the data in Excel spreadsheets and deliver the tagged financial statements in iXBRL.
Long-term, we expect the use of digital-first software will be embedded into most reporting systems and the AFR reporting process will start with some scope-setting process, for example, an ESEF Report with 5 primary statements, plus a number of disclosures and standard chapters to summarise the business messages. The content for each section may be prepared and tagged individually, then combined to generate the final tagged report in all the format(s) required by the regulations and audiences in your market.
Automating the Tagging Process
High quality tagging is another big issue for stakeholders. Irrespective of software used, it takes experts with knowledge of both financials and XBRL to successfully tag the report. Many companies rely on third party expertise which needs careful monitoring and management but does not always receive the time. Could this tagging be automated?
Some XBRL software uses ‘fuzzy text’ mapping techniques which can appear to make identification of the ‘key’ information to be tagged look simple but, in practice, this results in many unsuitable tag selections. These tagging errors then take significant time and expertise to identify and to fix, so any benefit of automation is often lost.
Expert categorisation of the taxonomy elements can help make the mapping process more efficient. For example, UBPartner’s XBRL mapping tools use this approach, but it still needs experts to confirm that the right tag is selected.
However, the obvious choice is to use Artificial Intelligence (AI) and in particular machine learning to interpret the content, understand the taxonomy concepts and determine which tags to use. Large Language Models (LLMs), like Chat-GPT4, can analyse large amounts of text, but cannot identify the financial concepts without further information. XBRL International has reported on this topic recently after a piece of research by Patronus AI. More details can be found here.
We plan to cover a piece of research that UBPartner undertook on this, later this year, but so far, the evidence shows that the accuracy of AI for analysing complex disclosure content is patchy, and still needs significant human analysis to ensure compliance.
Can Audit benefit from Automation?
Financial auditing is an area that benefits greatly from the standardisation and validation that inline XBRL brings to annual financial returns. The documents can be validated and reviewed using tools such as the IXBRL Viewer or even more powerful analysis tools such as an XBRL database. Corporating’s Prism software is a good example of an attempt to help companies and auditors to better review their tagging. It includes additional quality checks and a database of the concepts used to tag similar reports. These offerings continue to improve and can only deliver more automation opportunities.
However, even these systems cannot fully expose issues where the wrong tag has been used for an element in a specific context, where there is only partial tagging, or where some parts of the report remain untagged. Again, AI may prove to be the answer to checking that the right tags have been used.
Improvements in each of these areas will help to automate the process of producing digital annual returns, and thus reducing errors and improving the readability for investors. So, when should software suppliers and companies start thinking about them?
The Time to Adopt iXBRL is Now
Enabling financial software users to use, track and validate the financial data all the way to the annual report is a huge benefit, enabling companies to feel confident in the accuracy of their numbers, enabling auditors to check the processes and the numbers early, and saving last minute changes and delays. Such automation has always been the goal.
As the technology and processes advance, now is the time for financial software vendors to add iXBRL to their products’ output capability. Either for integration and compatibility with HTML publishing tools, such as Pomelo or Reportl, or with their own system tools that produce simpler reports.
There are still several implementation challenges, outside of the underlying technology adoption issues, such as, many reporting frameworks such as the US SEC and ESEF have adopted different approaches to XBRL, which means a company cannot use the same tagging to be reported in the US and Europe; and similarly, sustainability initiatives at the ISSB (IFRS) and EFRAG (ESRS for CSRD in Europe) are developing inconsistent sustainability standards and taxonomies.
Regulators will always have pressures forcing divergence, and at every stage of implementation and usage this will create problems. 100% international standardisation in digital reporting drives costs lower and improves comparability for everyone in the supply chain.
The increased scrutiny and automation of analysis that publicly available standardised data provides like the Edgar database in the US and the EU’s plans for the European Single Access Point (ESAP), will increase the demand for iXBRL-based data and enable automated mass ‘crowd’ analysis of companies’ reporting.
This spotlight will place greater pressure on the quality of companies’ data, and in turn will further expand the usefulness of the information and demands for more tagging.
Conclusions
It is clear that international reporting is shifting towards a ‘digital first’ future using an AI-friendly iXBRL format. As software matures, iXBRL can become a crucial interchange format between complementary systems.
Forward-thinking reporters, their advisers and software developers will see the digital changes in reporting as a positive opportunity to transform their processes and data – to fully meet compliance requirements and to ensure that data is always visible, easy to use and available for analysis by all stakeholders.
The authors are Rob Riche of Friend Studio, Thomas Verdin of Tesh-Advice and Martin DeVille of UBPartner.
This article assumes readers have knowledge of digital reporting regulations, XBRL tagging, HTML, and the limitations of current reporting software and processes. Please send questions, comments, corrections, and any alternative ideas to info@ubpartner.com